1. Rédei: Die Kompillierungsarbeit und das UEWb
Als eine permanente Einrichtung beherbergt das Sprachwissenschaftliche Institut der Ungarischen Akademie der Wissenschaften eines der weltweit größten etymologischen Archive für die uralischen Sprachen. Unter der Hauptherausgeberschaft von Károly Rédei 1988-91, wurde das epochale Uralische Etymologische Wörterbuch I-III, Budapest, Akadémiai Kiadó 1986-1988 und Wiesbaden, Harrassowitz 1988-1991 (im folgenden UEWb) herausgegeben. Seither gilt das UEWb als der aktuelle Forschungsstand (vgl. Lakó1987, Kiss 1992, Schiefer 1991, Kulonen 1988, Kulonen 1996. Das UEWb stützt sich systematisch auf die bisherigen Forschungsergebnisse der Uralistik und präsentiert nach mehreren Jahrzehnten Arbeit den heute als wissenschaftlich fundiert angesehenen gemeinsamen Wortbestand der uralischen (finnisch-ugrischen und samojedischen) Sprachen. Das Werk ist den heutigen hohen philologischen Forderungen entsprechend mit großer Sorgfalt kompilliert und enthält eine strukturierte und übersichtlich geordnete Sammlung der uralischen Etymologien (1876 Einträge), belegt in 25 Hauptsprachen, ergänzt -- wenn erforderlich -- durch Dialektformen. Insgesamt werden im UEWb rund 157 uralische Sprachvarianten referiert: Zu den 25 Hauptsprachen kommen durch die Berücksichtigung der regionalen Variation noch 132 Dialekte. Im Entlehnungszusammenhang wird auf weitere 120 nicht-uralische Sprachen Bezug genommen. Die Wortartikel enthalten Verweise auf die Fachdiskussion (mit Literaturhinweisen). Im Kommentarteil gibt es eine Bewertung der Etymologien und ihre Einzelannahmen auf Lautgesetzlichkeiten, Bedeutungswandel onomatopoetische Herkunft u.ä. auch in Bezug auf abgelehnte Etymologien. Das UEWb stellt den gemeinsamen Wortbestand der uralischen Sprachfamilie dar. Die Etymologien sind als Uralisch, Finnisch-Ugrisch, Finnisch-Wolgaisch, Finnisch-Permisch und Ugrisch geschichtet und innerhalb der Schichten nach den jeweiligen rekonstruierten Formen sortiert. Die einzelsprachlichen Belege können mit Hilfe der 25 Hauptsprach-Register gesucht werden.
2. Molnár: Die Datenaufnahme und das Winword-Modell
Die Datenaufnahme begann bereits während der Publikation des Wörterbuches bei dem Budapester Akadémiai Kiadó und bei dem Wiesbadener Harrassowitz Verlag. Auf Initiative von Professor Csúcs ist das ganze Material des UEWb-s maschinenlesbar gemacht worden. Die Datenaufnahme erfolgte unter der technischen Leitung von Zoltán Molnár. Das WORD-System wurde deshalb gewählt, weil damals Microsoft die Bewältigung der für das UEWb unerläßlichen diakritischen Zeichen versprach (Molnár 1995). Die Lautwiedergabe erfolgt in dem UEWb mit Hilfe der in der Finnougristik üblichen Diakritika, die mit der Notation der International Phonetic Association nicht übereinstimmen. Diese Lautrepräsentation (cc. 400-500 Zeichen) sollte restlos maschinell erfaßt (d.h. eingegeben und angezeigt) werden. In der Tat sind im Rahmen des WINWORD-Systems die für die Wiedergabe der in der Uralistik gebräuchlichen Schriftzeichen (Diakritika, kyrillischen Schrift und Sonderzeichen) erforderliche Fonts praktisch alle als truetype fonts zur Verfügung gestellt worden. Es muß hier hervorgehoben werden, daß die Arbeitsleistung bei der maschinellen Erfassung der Daten die Grundlage aller anschließenden Manipulation der Daten bildet und daher die Arbeit der Gruppe von Sándor Csúcs, Zoltán Molnár, Mária Sipos, Beatrix Oszkó, Zsuzsa Salánki und Imre Csaba Nagy nicht hoch genug eingeschätzt werden kann.
Über diese Arbeit wurde auf dem Achten Finnougristenkongress in Jyväskylä in August 1995 berichtet und das WINWORD-System wurde vorgeführt (vgl. Sipos1995 und Csúcs et al.1995). Auch nach dem Kongress in Jyväskylä nach 1995 wurde an der Datenaufnahme weiter gearbeitet: Die Dateien waren vereinheitlicht und diversen Korrekturarbeiten und Bereinigungen wurden durchgeführt. Nutzung der Daten war jedoch an das WORD gebunden: die Daten waren zwar maschinenlesbar, aber nur als Textdatei verfügbar.
3. Das SQL-Modell von Fitschen
Im SS 1996 wurde ein Muster-Segment des UEWb-Materials (147 Lexikoneinträge) dem Institut für Computerlinguistik für Forschungszwecke zur Verfügung gestellt, auf dessen Grundlage die erste Diplomarbeit mit UEWDb-Thematik geschrieben worden ist (Fitschen 1997). Er bewältigte exemplarisch zwei Aufgaben:
Er stellte ein Datenbanksystem für den uralischen etymologischen Datenbestand vor und
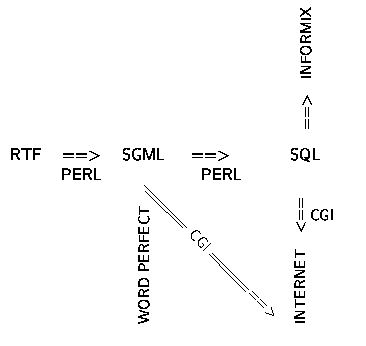
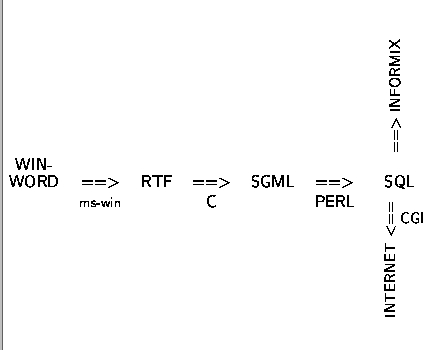
er überführte in zwei Schritten die ursprüngliche WINWORD-Text-Datei (1. RTF == > SGML und 2. SGML == > SQL) in eine (struktuierte) SQL-Datenbank unter INFORMIX:
Fitschen befaßte sich mit dem Vergleichsteil der Einträge und mit den Titelzeilen. Er leistete Pionierarbeit bei der Überführung der WINWORD-Daten in SQL-zugängliche DB-Repräsentation. Die SGML-Ebene bei Fitschen ermöglichte die automatische Erkennung von Kodierungsfehlern.
Auf Einladung des CL-Institutes der Universität Koblenz-Landau überprüfte Dr. Tamás Váradi (Sprachwissenschaftliches Institut der MTA, Budapest) das Umsetzungsverfahren von Fitschen in dem er sieben weitere Dateien von UEWb vom WINWORD-Format in INFORMIX DB-Format überführte. Als Ergebnis entstand die provisorische INFORMIX Datenbasis für alle Etymologien im UEWB.
Obwohl Váradi Fitschens Konzept weitgehend folgte und kein neues Modell anstrebte, eröffnete sich durch Heranziehung von WORD PERFECT eine neue Perspektive im Überführungsverfahren, nämlich die eigenständige Nutzung der SGML-Ebene, die für Fitschen lediglich eine Korrekturfunktion hatte. Váradi wollte die SGML-Dateien als Text-Datenbasis benutzen: Der SGML-Modus von WORD PERFECT läßt nämlich die direkte Erkennung (und Nutzung) der Struktur der lexikalischen Informationen zu, lediglich die DTD muß aufgestellt werden Bátori,Németh,Váradi 1998> .
Váradi konvertierte alle Lexikoneinträge, sparte aber den Kommentarteil und die Bibliographie aus. Ausserdem förderte seine Konversion eine Reihe von Datenfehler zu Tage.
5. Die virtuellen Tastaturen von Németh und die Behandlung der Diakritika
Fitschen und Váradi haben die Datenbasis UEWDb aufgebaut. Das System war allerdings zunächst schwer zugänglich, da die Anzeige der diakritischen Zeichen mit HTML (außerhalb der WINWORD-Welt) noch nicht bewältigt war. Die Anzeigeproblematik wurde durch die Qualifikationsarbeit von Krisztián Németh 1999 entscheidend vorangebracht:
Um die diakritische Zeichen überhaupt anzeigen zu können, wurden GIF-s entwickelt und als fertige "Bilder" eingefügt. Diese Behelfslösung war umständlich, und wenig flexibel: Die diakritische Zeichen statisch, da die Bilder nicht vergrößert werden könnten.
Daher entwickelte Németh für den uralischen Zeichensatz HTML-taugliche TrueType
Fonts und bereinigte auch einige Fehlbelegungen in den bisher benutzten Fonttabellen.
Er entwarf virtuelle Tastaturen, die die Eingabe der diakritischen Zeichen ermöglichen.
Die TrueTypeFonts in NETSCAPE sind flexibel und dynamisch und (ihr Qualität konkurriert mit den WINWORD-TruTypeFonts).
Bereits vor der Fertigstellung der neuen TrueTypeFonts war für Németh allerdings klar, daß sie nocht nicht die endgültige Lösung sein werden. Mehr Persspektiven bat das Unicode-System mit dem gezielten Vermehrung des Kodierungsraumes auf 2 hoch 16 = 65K. Die neuen UNICODE-konformen Fonts für die Uralische Etymologische Datenbasis hat Németh konzipiert. Die Realisierung erfolgte allerdings erst mit Hilfe von Frau Saliha Rabah. Die technische Gestaltung der Unicode-Fonts ist in dem Papier Unicode-Zeichensatz für die UEDb vorgelegt.
6. Puttkammers Konversion: UEDb mit XML und Unicode-kompatiblen Zeichensatzes
Die Datenkonversion von WINWORD zu einer DM-Repräsentation (SGML/SQL) erwies sich langwieriger als nach den ersten Experimenten von Fitschen und Váradi angenommen worden war:1. der gesamte Datenbestand mußte konvertiert werden (also über den Vergleichsteil hinaus auch die Kommentare und der Referenzteil). 2. Die db-mäßige Integrität der konvertierten Daten mußte gewährleistet werden. Dazu kamen noch die Forderungen nach Effizienz und eine differenzierte Wiedergabe der Diakritika.
Puttkammer hat seine Konversion in Sommer 2001 abgeschlossen.
Als Ergebnis der bisherigen Arbeiten steht heute ein implementiertes UEDb-Modell zur Verfügung, das Vorführungen und Experimentieren mit dem System ermöglicht.
Letzte Änderung: 9.02.2005